
Three weeks of green CI. A flow that never executed the way the spec said it should. An agent that, given the choice between the documented OAuth dance and a debug shortcut that happened to return the same HTTP status, picked the shortcut. We fixed the documentation. The next test came out right on the first try.
That bug is the small story. The bigger story is the harness engineering we did around it — over three and a half months, alongside normal feature work, on a Spring Boot microservice — the MCP Servers Registry — that manages server configurations and OAuth flows. Fifteen end-to-end suites. 162 test steps. CI wall-clock flat at three to four minutes while coverage grew five times, and a fivefold drop in commits per test step as the harness matured. A pipeline where four specialized AI agents propose, write, review, and run E2E tests, and where the way we move work between them is itself the artifact we are now optimizing. This post is the engineering tour of that harness — what we built, what we measured, and what we would warn the next team about.
Tests were green. The agent was testing the wrong thing.
Open the CI dashboard. Green for three weeks. A new OAuth test had been merged, the suite added one more dot to the row, and nobody had a reason to look harder. The discovery did not come from staring at the test. It came from the Planner agent — one of four we run on this codebase — flagging a coverage gap while drafting a new scenario. The "real" OAuth flow it was looking at, the one with discovery and Dynamic Client Registration (DCR), was not exercised anywhere.
Tracing the gap led back to the existing test. It had been calling an internal debug endpoint instead of the discovery and registration calls the contract described. The HTTP statuses lined up. The assertions passed. The test was wrong about which flow it was testing — and "wrong" had been silent for three weeks of merges.
That endpoint existed for a good reason. Debugging OAuth against external MCP servers is hard, and a shortcut that hands you a working token end-to-end saves hours. The endpoint is internal to the service, fully admin-gated, and not exposed in production — it exists so engineers can debug OAuth integrations without losing an afternoon. The endpoint was never the problem. The problem was that the API contract did not say "for local debugging only; not part of the OAuth flow." The agent saw an endpoint that produced the right status at the right step, and used it.
We didn't fix the test. We fixed the documentation.
We will come back to the mechanics of that fix later in the post. We start here because this incident is the cleanest statement of the principle the entire harness is built around: test quality is a function of what the agent receives as input. The spec decides. The agent executes. We do iterate the agents and skills too — more accurate planners, more specialized review skills — but that work moves slowly compared to the context the agents read, which changes every sprint. It is a small simplification, but mostly true in our case: the leverage is in the spec, not the model. Once you accept that, the question shifts from "how do we get better agents?" to "what is the system that produces the spec the agent reads, and how do we evolve it without slowing delivery down?" The rest of this post is the answer we have so far.
Why E2E became the place the harness took shape
One of us joined the service while it was under delivery pressure. Documentation was a handful of API examples in Postman JSON format. The unit and integration tests had high coverage and low business value — vibe-coded by AI, they checked HTTP 200s and response shapes, not behaviour. CI was green on every push and told us almost nothing.
We had a choice about where to start. We picked E2E deliberately. Three reasons. First, an E2E suite asserts on business outcomes — "the admin published a server and it now shows up in the list" — which is exactly the layer of behaviour the existing tests were not protecting. Second, an E2E test exercises the integration boundary, which is where a brownfield Spring Boot service hides most of its scars: WireMock stubs for external dependencies, OAuth flows, secrets handling, real database transitions. Third — and this is the part that surprised us — an E2E suite makes the missing documentation visible. You cannot write a useful E2E test without naming the precondition, the endpoint, the expected status, and the external stub. Either the artifacts that name those things exist, or they do not. The suite forces the question.
The work happened over roughly three and a half months, in sprint-sized increments. Ten weeks on the foundation — C4 system and container diagrams (kept in Mermaid alongside the code, generated with AI from a separate architecture spec and refreshed when the spec changes), a real API contract, a CONTRIBUTING.md, a README.md, and the first scenarios in what would become SCENARIOS.md. CI that verified instead of only building. Two weeks of harness work on top — CLAUDE.md as the index the agent reads first, plus the four-agent pipeline (Planner, Implementer, Reviewer, Runner) we still run today. Then the suites started landing. March: three suites and 33 steps. April: nine new suites and 83 new steps. May 1–11: three more suites and 46 steps — eleven days, more than half of April's step count. We will get to the data in detail. As a rough order of magnitude, the foundation phase took about a day per sprint per engineer; the expansion phase, a few hours.
Mapped onto the Harness Model maturity matrix, the journey is the climb from Stage 1 (no AI process, tribal knowledge, ad-hoc tests) into Stage 3 (human-in-the-loop with structured documentation and an agent that generates from it). We did not jump. We climbed. If you are earlier on the curve and still asking where to start with AI-assisted development at all, our companion post on how to start with AI-assisted development today covers the thirty-minute experiment we recommend before any harness work. The same documentation that onboarded a new engineer turned out to be exactly what the agent needed, and that coincidence is the part we keep coming back to. There is no "AI documentation" in this repository. There is just documentation, written well enough that an agent can use it.
Domain aggregates: where the spec actually starts
Before any SCN, before any contract, there is a smaller artifact we under-invested in for the first few weeks and have been correcting for ever since: the domain aggregate — DDD's aggregate, sketched on one page. A single business concept with its states, its lifecycle transitions, who owns each transition, and the invariants that survive across them.
For the MCP Servers Registry, the aggregate looks roughly like this:
Domain aggregate: server configuration (MCP Servers Registry)
States: UNPUBLISHED -> PUBLISHED
Owners: admin edits (create, update, publish, unpublish)
power user reads (selects for runtime, never edits)
Transitions: create -> UNPUBLISHED
update (admin) -> UNPUBLISHED
publish (admin) -> PUBLISHED
unpublish (admin) -> UNPUBLISHED
Invariants: a power user only sees PUBLISHED entries
server URL and configuration ID are distinct fieldsThis kind of artifact belongs before SCNs in the spec lineage, not alongside them. Two reasons. First, every SCN that touches "publish" or "select" needs the same vocabulary; without the aggregate, three SCN authors invent three slightly different vocabularies, and the agent learns the inconsistency. Second — and this is the part the OAuth bug pointed at — most agent misbehaviour we have traced back to spec problems came from missing aggregate-level knowledge, not missing SCN steps. A field called "server URL" being silently overloaded to also carry a configuration ID is the kind of confusion that the aggregate catches and an SCN does not.
We use AI in this step too, but as an elicitor rather than a writer. A skill in the repository prompts the engineer through "what are the states, who owns each transition, what are the invariants," and produces a draft aggregate the team edits. The work that takes time is naming the states and the owners — exactly the work the SCN cannot do for itself. The aggregate is short, lives next to the API contract, and is referenced by every SCN that crosses its boundary. The next section is where it gets cashed in.
The SCN format — and where it sits in the spec lineage
Every E2E test starts as a scenario in SCENARIOS.md. We call them SCNs. The format is intentionally small.
SCN-001: Admin configures MCP server
Preconditions:
- Application is healthy (actuator/health -> UP)
- Admin authenticated (identity headers + userType=ADMIN)
- WireMock as stub for the external MCP server
Steps:
1. Admin reads the current server list.
GET /mcp-servers/config -> 200
2. Admin tests the connection to a new server; tool discovery succeeds.
POST /mcp-servers/test -> 200, discover tools
3. Admin saves the configuration as UNPUBLISHED.
POST /mcp-servers/config (state=UNPUBLISHED) -> 200
4. Admin publishes the configuration.
POST /mcp-servers/config (state=PUBLISHED) -> 200
5. Admin re-reads the list; the new entry is present.
GET /mcp-servers/config -> 200, count + 1Five steps. Three preconditions. Each step has an HTTP verb, an endpoint, and an expected outcome. That is the entire interface between human intent and the agent.
The format is not new. Specification by Example and Gojko Adzic's work on it predate this by more than a decade. BDD tools like Gherkin gave us Given/When/Then. Contract testing tools like Pact push the same idea down to the wire. More recently, Martin Fowler's writing on structured prompt-driven development and projects like GitHub Spec Kit treat structured prompts as a first-class engineering artifact. SCNs sit inside that lineage. The shared idea is older than any of the tooling: there is a layer of artifact above the test, written in human language, that captures intent precisely enough to survive change.
The difference here is who the consumer is. Gherkin is the test, executed by Cucumber. SCN generates the test, written in Python by an agent. That distinction is why we keep the SCN minimal. The agent fills in fixtures, WireMock stubs, assertions, and cleanup; we keep the document at the level a product manager could read. If we pushed the SCN to be more precise, we would be writing the test in slow motion. If we let it drift looser, the agent would invent details.
The other job the SCN does — and we keep underlining this — is to act as a contract. It is the precise statement of what "this flow works" means, written before the test exists, and it stays the contract whether a human drafts it from a feature ticket or the Planner drafts it from a contract delta. The SCN is also a diagnostic: somebody has to sit down and write the steps, preconditions, and success criteria. If neither the human nor the planner can, the flow is not understood yet — and no model will fix that for you.
If you can't write the scenario, the agent can't either.
We treat that sentence as a hard rule. To make the diagnostic concrete, here is an SCN that does not work — and the small set of edits that does:
SCN-XXX (weak): User publishes server
Steps:
1. Save and publish the server configuration -> success
2. Check that the server is listedThe verbs are missing. "Success" is unspecified. There is no precondition about authentication or what the list contained beforehand. An agent reading this writes a test that calls some endpoint with some payload and asserts a 2xx — and the test is green for the wrong reasons.
SCN-XXX (fixed): Admin publishes a new MCP server
Preconditions:
- Admin authenticated (userType=ADMIN)
- Configuration list is empty
Steps:
1. Admin saves a new server configuration as UNPUBLISHED.
POST /mcp-servers/config (state=UNPUBLISHED) -> 200
2. Admin publishes the saved configuration.
POST /mcp-servers/config (state=PUBLISHED) -> 200
3. Admin re-reads the list; the configuration is PUBLISHED.
GET /mcp-servers/config -> 200, count == 1, entry is PUBLISHEDSame intent. Wholly different prompt. The fix is not in the agent or the model — it is in five lines of plain text that a human writes, or the Planner drafts and a human approves, before regenerating.
The OAuth bug, in mechanics
Back to the OAuth bug, this time with the wiring. We want to walk through it because it is the clearest example we have of "fix the spec, not the test" paying off in a single afternoon.
The correct OAuth Dynamic Client Registration (DCR) flow looks like this:
| Correct OAuth DCR flow | What the agent did |
|---|---|
GET /.well-known/oauth-authorization-server |
skipped |
POST /register (Dynamic Client Registration) |
skipped |
GET /authorize |
GET /authorize |
POST /token |
POST /token (against the debug endpoint) |
GET /resource |
GET /resource |
The agent skipped discovery and registration and used the debug endpoint to obtain a working token directly. The remaining calls all succeeded. The test asserted that a resource came back. CI was green.
The fix was two lines of work, neither in the test file:
## OAuth endpoints
+### POST /oauth/debug-token
+For local debugging of OAuth integrations only. NOT part of any production
+OAuth flow. Tests MUST go through /.well-known and /register first.
### GET /.well-known/oauth-authorization-server
Returns the authorization server metadata used by the DCR flow.We added the missing line to the API contract describing what the debug endpoint is for. Then we wrote a detailed OAuth request-flow diagram into the architecture docs — a Mermaid sequence diagram listing the correct endpoints in order, AI-generated from our OAuth spec following the same pattern as the C4 diagrams.
On the next Planner iteration, the Planner discovered the new file as part of its context, noticed that the existing test did not match the documented flow, and proposed a regenerated test. We accepted it. The new test made the discovery call, performed the registration, used the registered client to get a token, fetched the resource, and asserted the lot. One shot. Fix the spec, not the test: write the missing artifact, let the harness re-read it, accept the corrected test.
The agent was not confused about OAuth. It knew the protocol perfectly well. What it was missing was the boundary statement — which endpoints in our service are part of the flow and which are not. That is exactly the gap an aggregate-plus-contract pair is supposed to close, and the lesson we took out of the incident was that the domain aggregate for "MCP server OAuth integration" had been implicit in our heads and absent from the repository.
The implication compounds both ways. Every future OAuth scenario the agent generates now starts from the corrected understanding — it cannot accidentally use the debug endpoint. Every other agent, and every human reading the docs for onboarding, gets the same clarification for free. A line of API contract is doing more work than a fix in a single test could.
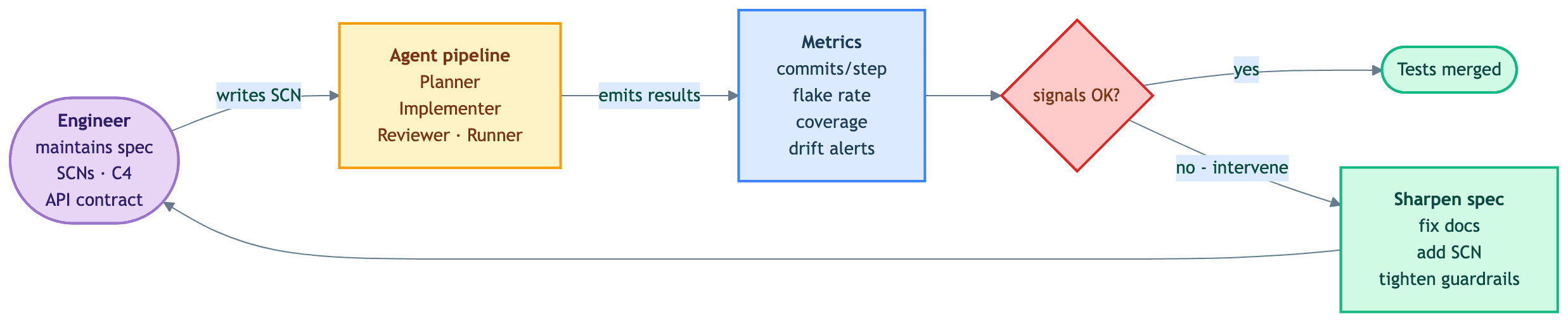
The artifact loop, plus what's upstream and downstream of it
The artifacts are not isolated documents. They form a loop. The loop is what makes the investment compound.

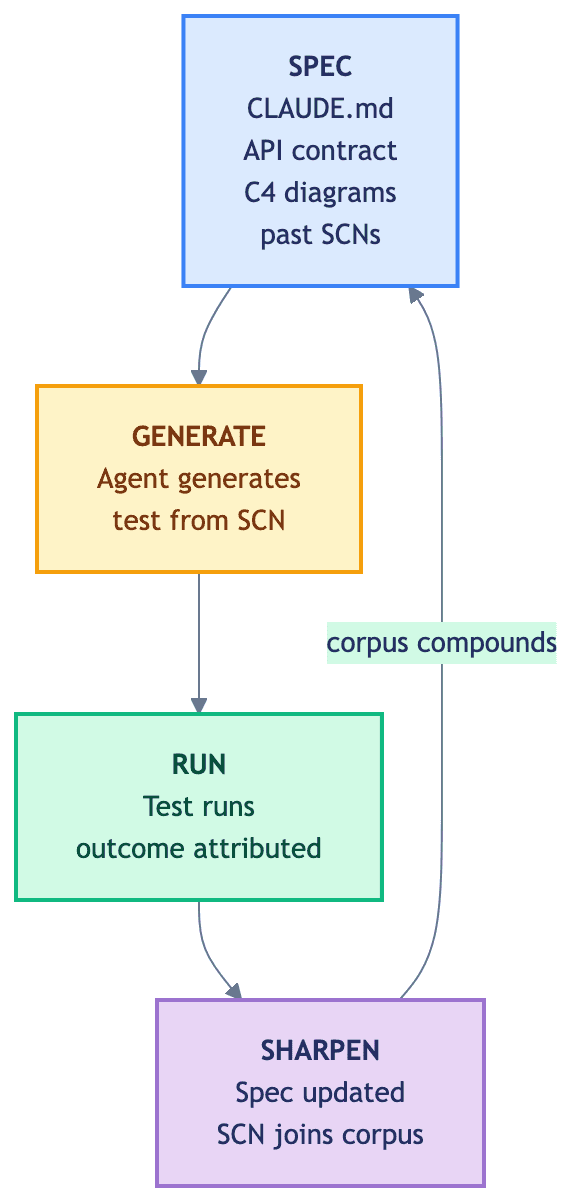
That diagram is the inner loop — the one we sketch first when someone asks how the harness works. SPEC, GENERATE, RUN, SHARPEN. We have linked it before to Mitchell Hashimoto's harness engineering idea: any time an agent makes a mistake, you engineer a solution so it never makes that mistake again. The artifact loop is one shape that engineering takes. Custom linters and structural tests — like those in our Python architecture-tests post — are another. Both belong in the harness.
Concretely, skills live at .claude/skills/<name>/SKILL.md, agents at .claude/agents/<name>.md, and slash commands at .claude/commands/<name>.md. The orchestration sits in a slash command — /e2e/scenario — that walks the four agents through the pipeline with a human approval gate after the Planner step. Each agent in turn calls a focused skill: the Implementer uses e2e-scaffold for the suite skeleton (templates for the test file, docker-compose, and WireMock layout) and wiremock for stub generation; the Runner uses e2e-run to execute the suite in an isolated container. Conventions live in the skills; control flow lives in the command; the agents are the things that get reviewed.
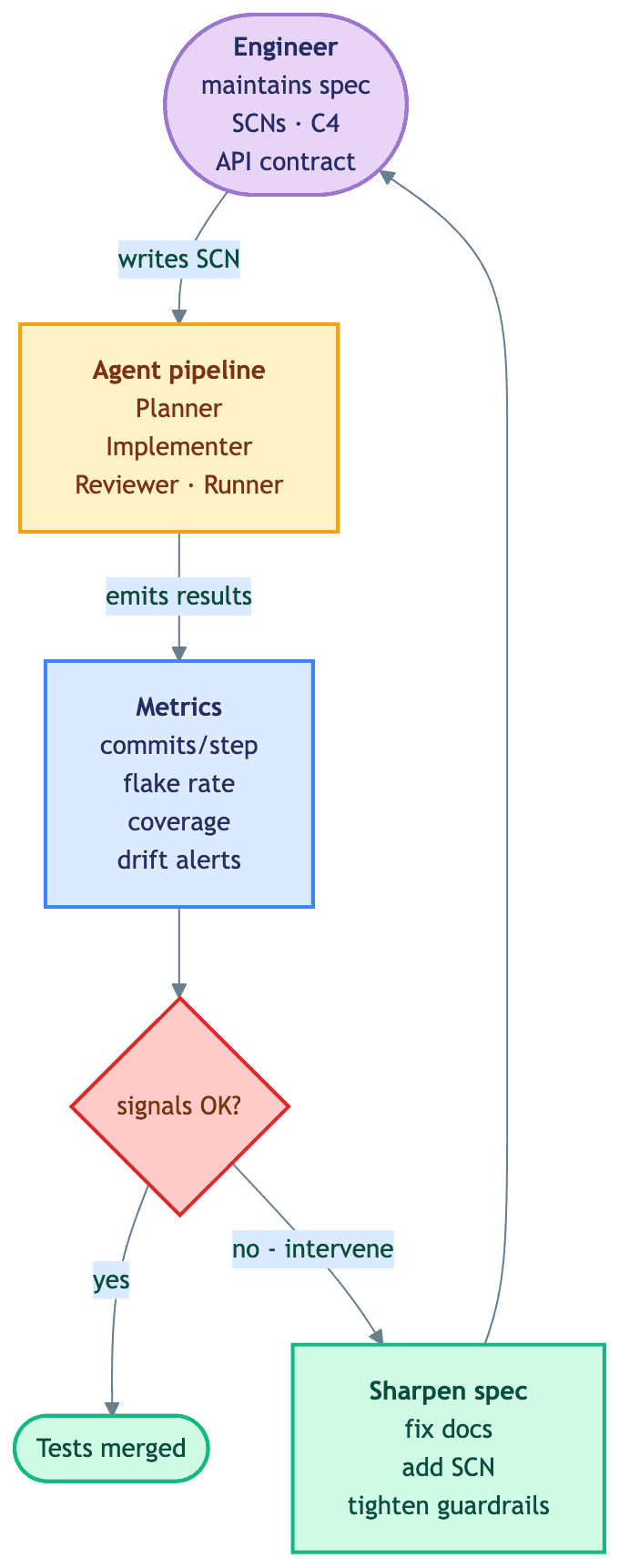
What the artifact loop hides is the SDLC pipeline that surrounds it. Once we started building specialized agents for domain elicitation, contract drafting, and SCN authoring — not only for test generation — a wider loop became visible. The diagram below is how we draw that loop today.

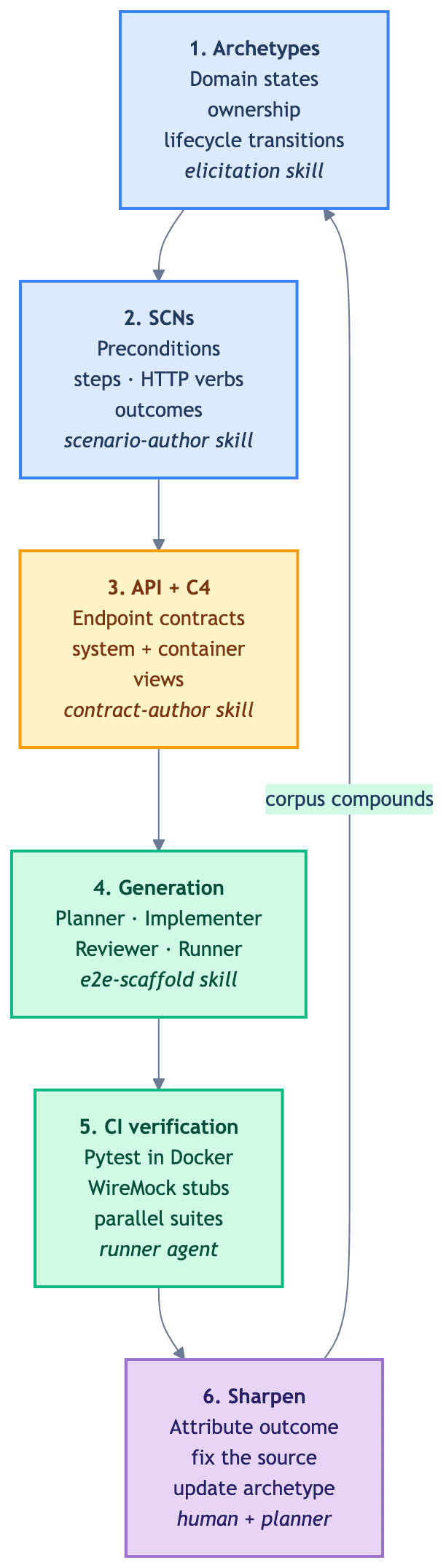
The six stations on the diagram correspond to the five states a scenario moves through.
Analyzed — the scenario's domain aggregate and SCN exist. The domain skill elicits the states and invariants, the scenario-author skill drafts the SCN, and the team edits.
Proposed — the contract-author skill writes the API contract and the C4 diff against the aggregate.
Approved — the /e2e/scenario slash command drives the Planner / Implementer / Reviewer / Runner agents to produce the pytest file, WireMock stubs, and docker-compose.yml updates. Each agent calls the relevant skill (e2e-scaffold for the suite skeleton, wiremock for stubs, e2e-run for execution), so the project's E2E conventions live in one place.
Implemented — CI runs the suite. The Runner attributes each outcome — pass, fail, flake — to a cause: spec, application code, test code, or infrastructure.
Sharpened — the cause gets fixed at the source. A fuzzy precondition becomes concrete, an ambiguous endpoint gets a paragraph, the aggregate gains a state if it needs one.
One honest caveat. The Sharpen step is not pure automation. The Planner surfaces gaps, the Runner attributes outcomes, a human decides what to write. Outcome-to-spec attribution is a classification problem we can in principle automate further — we are not there yet. More on that gap in the human-in-the-loop section.
The data: 15 suites, 162 steps, and the shape of the curve
Three months after we migrated the first suites to pytest, we have 15 suites and 162 test steps committed. The growth was not even.
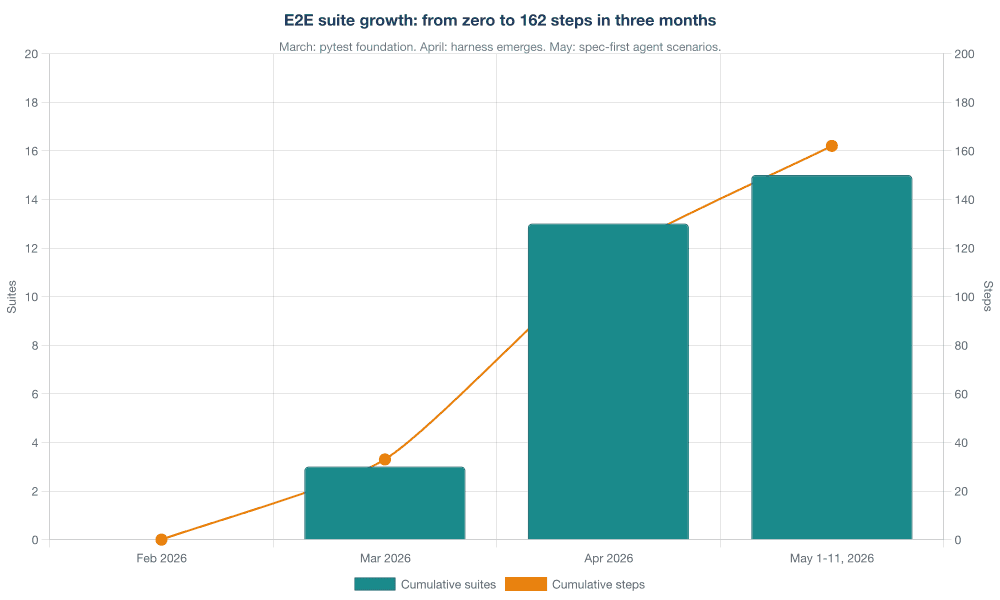
March was the pytest foundation: three suites and 33 steps, written by two engineers who were also inventing the conventions as they went. April was the expansion: nine new suites and 83 new steps, with SCENARIOS.md, the e2e-scaffold skill, and shared WireMock stub patterns emerging in parallel. May, through publication on the 12th, added three agent-management suites in eleven days — and those are the ones where spec-first discipline paid its largest dividend.
The clearest signal of compounding is commits per test step: how many commits the team needed to land a working suite, divided by the number of test steps in it. Here is what that looks like in the git log.
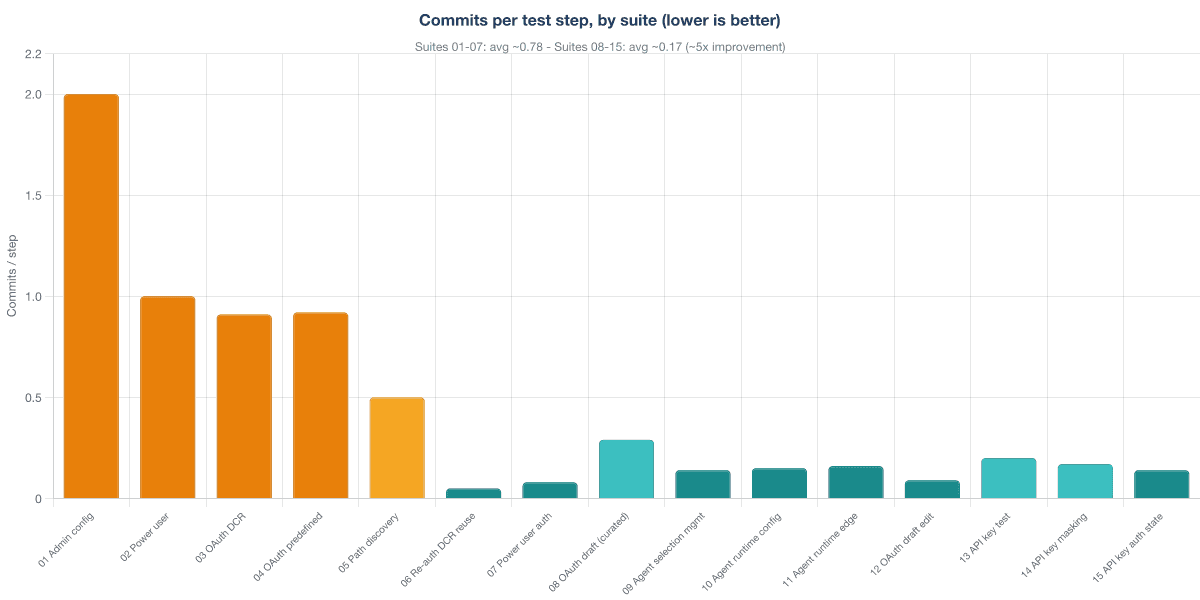
Suites 01 through 07 averaged about 0.78 commits per step — the agent's work while the harness was still thin. Scenario format in flux. API contract gaps still being discovered. WireMock conventions not yet shared. Suites 08 through 15 averaged about 0.17 commits per step, a roughly five-times improvement. Suite 06, "Re-auth DCR reuse," is the most striking single point: 20 steps, one commit. The agent reused DCR work it had already verified in earlier suites; the SCN corpus itself was now part of the spec.
There is a quieter, more organizational signal in the same git log. The principal software engineer on the team committed SCENARIOS.md alone first — a commit with no test code, only scenarios — and then delivered three agent suites in a single implementation commit afterwards. Spec-first separation, visible in git. A software engineer on the team writes scenarios and implementation together in one commit rather than ahead of it; growing engagement, not yet full separation. We did not mandate the spec-first pattern in a process document. It showed up in the commits as soon as the harness made it cheaper than the alternative.
The third chart is the one we did not expect.
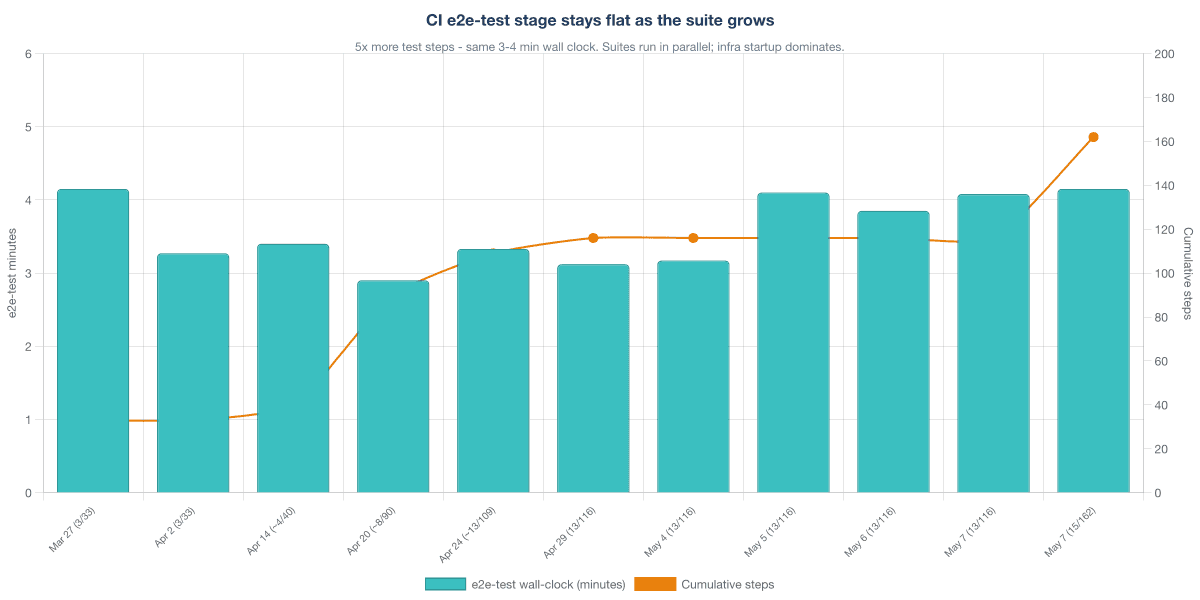
The e2e-test stage of our Jenkins pipeline went from three suites and 33 steps to fifteen suites and 162 steps — and the wall-clock barely moved. Every CI run still finishes E2E in three to four minutes. Two changes did most of the work. We optimised how we reconfigure the environment between suites — re-prime WireMock and reload stubs, do not restart the application — and we reimplemented the test runner from bash to Python, which dropped per-step execution time substantially. What dominates the three-minute budget today is the application Docker image build and startup, including database schema setup; that is the fixed cost the growing step count gets amortised against. The next section is where we cash in on that property.
A reminder we keep repeating to ourselves: three months and one team is not a controlled experiment. The dataset is small. We were the variable that changed the most. The numbers are visible, but the trajectory is what we were trying to see, not the absolute deltas.
The Docker image and harness build: making prod-like the default
A harness is not only documentation and agents. It is also the infrastructure the tests run against. Three engineering decisions did the most to keep agent-generated tests honest.
One production-shaped image, curated overrides only
The application Docker image used by the E2E suites is the same image that runs in staging and production. No @Profile("e2e") bean tree, no @TestConfiguration that swaps in fakes at boot. The only thing the E2E run does is apply a small, curated set of Spring profile overrides — logging, the WireMock stub URLs, and a couple of JVM options.
# application-e2e.yaml - the entire override surface
logging:
pattern.console: "%-5level %logger{36} - %msg%n"
level.root: INFO
mcp:
external-server.base-url: "http://wiremock:8080"
oauth.authorization-server-url: "http://wiremock:8080/oauth"
spring:
datasource.url: "jdbc:postgresql://postgres-e2e:5432/mcp"The discipline here matters more than the file's contents. If the production image cannot satisfy the test, the test is the place to argue, not the image.
Per-suite docker-compose and the suite_containers fixture
Each suite has its own docker-compose.yml next to its tests, declaring the WireMock instances it needs and an optional auth proxy when OAuth is in play. Suites share the application's Docker network so they can reach it, but each suite owns its stubs.
services:
wiremock:
image: wiremock/wiremock:3.5.0
networks: [e2e]
volumes:
- ./wiremock:/home/wiremock
command: --port 8080 --verbose
networks:
e2e:
external: true
name: mcp-config-e2eA shared conftest.py exposes a session-scoped suite_containers fixture that handles the lifecycle. The skeleton below is illustrative — the project polls health endpoints with a small retry helper rather than the testcontainers built-in:
from testcontainers.compose import DockerCompose # custom health-check polling below
@pytest.fixture(scope="session")
def suite_containers(suite_dir, app_logs_dir):
compose = DockerCompose(context=suite_dir, compose_file_name="docker-compose.yml")
compose.start()
try:
wait_until(lambda: wiremock_admin_ready(compose) and proxy_healthy(compose))
yield compose
finally:
save_app_logs(compose, app_logs_dir)
compose.stop()Sharing a single WireMock across suites was the obvious starting point and the wrong one — stubs leaked, recordings overlapped, debugging a flake meant guessing which suite poisoned the global state. Session-scoped UUID fixtures (test_run_id, workgroup_id, user_id) handle data isolation the same way, even when suites share an app instance.
JVM DNS cache and HTTP keep-alive
This is the fix that earned the flat CI curve. Between suites, Docker restarts the WireMock containers and they get new IPs. The JVM's default DNS cache (indefinite TTL) and HTTP keep-alive (reused TCP connections) kept the application talking to stale container IPs — which meant restarting the app between every suite, and the wall-clock budget evaporated.
Two files, mounted into the application container as Paketo buildpack layer overrides — a Cloud Native Buildpack mechanism that binds small files into the running image without a rebuild. If your image is built differently, use a Docker bind mount or bake them in.
# e2e/java-security-e2e.properties
networkaddress.cache.ttl=0
networkaddress.cache.negative.ttl=0# e2e/jvm-e2e-options.append
-Dhttp.keepAlive=falseWith these in place, the JVM resolves DNS through Docker's 127.0.0.11 resolver on every call and never reuses a TCP connection across suite boundaries. The app no longer needs to restart between suites. The e2e-test stage stays at three to four minutes — image build and schema setup dominate the budget today, and we watch the curve on every CI run.
A caveat for modern Spring Boot stacks: -Dhttp.keepAlive=false only covers HttpURLConnection-based clients. If your service uses RestClient, WebClient, or Apache HTTP Client 5 for outbound calls, configure keep-alive timeouts on those clients explicitly — the system property does not reach them.
Specialized agents, skills, and commands across the SDLC
Today the test pipeline runs four agents — Planner, Implementer, Reviewer, Runner — with a single human approval gate after the Planner step. Each one has a narrow job. The Planner identifies coverage gaps and turns business intent into SCN drafts. The Implementer generates the Python test, WireMock stubs, and docker-compose.yml updates from the SCN, using the e2e-scaffold skill for project conventions. The Reviewer checks the diff against style rules, the API contract, and the existing test corpus. The Runner executes the suite in an isolated container and reports the outcome.


In the matrix's vocabulary this is human-in-the-loop, Stage 3 on the Human-Agent Interaction dimension. It is where most teams running agent pipelines on production code sit, and for a reason: we do not yet have a metric that lets us safely skip the plan review. Across fifteen scenarios, that is fifteen approval gates total — one per scenario, between the Planner's test plan and the Implementer that turns it into code. Each gate is five to fifteen minutes of human attention in our experience; the team is still calibrating what "good" looks like for the plan the Planner proposes, and that is where the time goes. That is the bottleneck the data already shows; the commits-per-step above 0.10 are usually not the agent doing twenty revision rounds — they are the agent doing the work in one pass and the human approving and adjusting the plan in two or three.
The direction we are building toward is wider than the test pipeline. The SDLC harness loop in the previous diagram already shows where we are headed: domain analysis, scenario authoring, contract drafting, generation, verification, and sharpen — each station served by a specialized agent or skill, with the human moving from per-step approver to system editor. The shorthand for that state is human-on-the-loop.
We will not pretend we are there. Three things we do not have yet:
- a quality metric we trust enough to gate merges on (today, commits per step is a lagging proxy);
- automated drift detection that ties contract changes to affected SCNs and forces a regeneration;
- a flake-rate signal that distinguishes infrastructure noise from real regressions.
This is exactly the matrix's Stage 3 → Stage 4 transition on Verification & Quality and Human-Agent Interaction, and it is the direction the Harness Model post frames in detail. We are doing the work. We are not writing the post yet that says we are finished.
The shape we expect the next two months to take: more specialized skills upstream of test generation (a contract-drift detector, a domain-aggregate refiner), more outcome attribution downstream (a Runner that can tell "the spec is wrong" from "the application code is wrong" automatically), and a quality metric we trust enough to merge on. None of those alone is dramatic. Together, they collapse the number of approval gates the engineer has to walk through, and they do it without giving up the ability to catch a debug-endpoint shortcut before it ships.
Traps when moving the team along the harness maturity stages
Moving from "we have some AI-assisted coding" to "agents generate E2E tests from SCNs and contracts" is not a single jump. It is a sequence of small moves along the dimensions in the maturity matrix. Six traps cost us the most time at the transitions.
Documentation accuracy becomes load-bearing. When humans were the only readers, "mostly right" docs were fine; people noticed contradictions and asked. Agents do not ask. They take the contract at face value. A field marked optional that is actually required produces a wrong test every time. The Stage 2 → Stage 3 transition is when documentation stops being a productivity aid and becomes correctness infrastructure.
Tribal knowledge becomes a correctness ceiling. The OAuth bug came from tribal knowledge — "everyone knows the debug endpoint is for debugging" — that had never reached the contract. While humans wrote the tests, the gap was invisible because the author also knew. The moment agents wrote the tests, the gap surfaced as a wrong test in production CI. Stage 2 → Stage 3 again, on the Context Engineering dimension.
Vibe-coded existing tests sabotage the new ones. The unit and integration tests we inherited were technically high-coverage and business-low-value. When the agent reads tests/ looking for examples of how the codebase asserts things, those tests teach the wrong style. We had to mark a chunk of them as "do not learn from" and write a CLAUDE.md section pointing the agent at the SCN-driven E2E suites as the canonical examples. This is the trap at Stage 3 → Stage 4 on Verification & Quality.
API contract drift between controller and OpenAPI spec. Once the agent reads the OpenAPI spec instead of guessing from controller code, the controller stops being the source of truth — but only if you defend that move. The first time a developer in a hurry adds a query parameter in the controller and forgets the OpenAPI annotation, the agent writes a wrong test against the right code. We caught two of these in April and a pre-commit hook in the contract repository now blocks the drift. Stage 3 → Stage 4 on Context Engineering.
WireMock JSON mappings as first-class contract artifacts. The first instinct, ours included, is to treat WireMock stub JSON as "test fixtures" and let each suite invent its own. After the second OAuth bug that came from a stub that was technically wrong about the external service's response shape, we moved the WireMock mappings into a curated directory, tagged each with the upstream contract version they represent, and started reviewing them on PRs alongside the application code. Stub correctness is contract correctness. Stage 3 → Stage 4 on Verification & Quality.
Skipping sprint-aligned investment. The most expensive trap is the one that does not look like a trap. The temptation, when the harness is taking shape, is to run a "documentation sprint" — three days of writing docs, then back to features. We tried it once. The docs were stale by week three. What works for us is sprint-aligned investment: every sprint, the harness gets one of its dimensions sharpened — a new skill, a contract clean-up, a Runner improvement. The pace is unglamorous; it is also the only pace that produced the curves above. Stage 1 → Stage 2 on Process and Workflow, and the trap that decides whether the whole journey starts at all.
The matrix's brownfield reality check applies directly: stages 1 through 3 work on brownfield systems, but Stage 4 — systematic harness with mechanical verification — assumes a level of architectural cleanliness that legacy code rarely has. Our service was extracted from a larger one, with real organizational scars, and even then we needed ten weeks of foundation work before agent-generated tests were trustworthy. A genuinely legacy system would need that work to land first on a single bounded module before any agent-driven test generation made sense.
The honest framing is this: harness engineering for E2E does not skip the boring work. It rewards teams that did the boring work, and it punishes teams that did not.
For Monday — write one SCN, sketch one aggregate
If you want a concrete next step that costs you nothing in tooling and an hour of attention, do two things.
First, pick one critical business flow in your service that has no E2E test, and write the SCN. A scenario ID. Three preconditions. Three to six steps with an HTTP verb, an endpoint, and an expected status. You do not need an agent. You need a text editor and the discipline to be specific.
Second, sketch the aggregate the SCN references — one paragraph. What are the states of the thing the scenario manipulates? Who owns each transition? What is the invariant the scenario implicitly assumes (the list contains only published entries, the user is authenticated, the configuration ID is distinct from the server URL)? You will discover, in the writing, what you do not yet know — and that is the answer to "can the agent write this test for me."
If the SCN comes out clean and the aggregate is one paragraph you would defend at a review, you have the shape of the spec the harness rewards. If either falls apart, fix the documentation that has to exist for them to make sense. Then come back to the SCN. Then, and only then, ask the agent.
This is the bet we are making, three and a half months and 162 steps in: better specs produce better tests; the spec corpus compounds; the harness is the system that holds the compounding together. The flat CI curve, the five-fold drop in commits per step, the fact that a 20-step OAuth re-auth scenario now lands in a single commit — none of that came from a smarter model. It came from documentation an agent could read, an aggregate small enough to keep accurate, a scenario format that respects the agent's lane, and a discipline that points every fix at the spec.
If you can't write the scenario, the agent can't either. Write one this week. Sketch the aggregate next to it. See what you learn from the writing alone.