Thoughtworks puts the task-vs-system gap as cleanly as anyone has: "It's like buying a Ferrari and driving it on muddy roads: the engine is powerful, but your arrival time is determined by road conditions and traffic." That image — borrowed from their work on Structured-Prompt-Driven Development — is what every productivity debate about AI tooling keeps returning to. The engine has changed. The roads haven't.
METR's February 2026 productivity update makes the same point in numbers. Its late-2025 cohort — 57 developers, 800+ tasks — puts both returning and newly recruited developers within a few points of zero, with confidence intervals wide enough to cross it in both directions. The honest read is not that AI helps or doesn't help — it is that task-level metrics are the wrong instrument for system-level questions.
Architectural governance is a system-level question. That is the layer this article is about — and the argument is that when individual teams reach Stage 3 in context engineering and workflow, governance is the dimension that determines what the platform actually delivers.
The productivity measurement trap
Per-task speed and platform throughput are not the same thing. If we make one developer 20% faster at writing a controller, the controller ships sooner. If two teams independently build incompatible contracts around the same bounded context, the integration cost is migration-level work — and it does not appear in any task-level study because it is not a task. It is a structural collision between systems that each shipped on time. Later in this article we walk through one concrete case: two teams both using "external integration server" to mean different things, which turns a documentation gap into a production incident.
This is why the METR caveat matters more than the central estimate. METR is measuring the right thing for the question it asks (does AI speed up individual tasks?), and the answer is "probably, with caveats that are getting harder to control." But that answer does not transfer to platform throughput — it is a different kind of question. Platform throughput is bounded by how fast a multi-team system can converge on correct cross-team decisions — and that is governed by shared vocabulary, shared diagrams, shared decision records, and the discipline of keeping them current. None of which appear in a task-level randomized controlled trial (RCT).
We will use the term harness throughout the rest of this article in the sense Birgitta Böckeler develops in her "Harness Engineering" piece: a harness is everything in an AI agent except the model itself.
Agent = Model + Harness
The harness is the context, the constraints, the verification — the system around the agent that turns raw model output into something a team can trust. Harness engineering is the practice of designing and improving that system, the same way you would design and improve a test suite or a CI pipeline.
The rest of this article is about what happens when the harness is built per-team but the system being governed is cross-team.
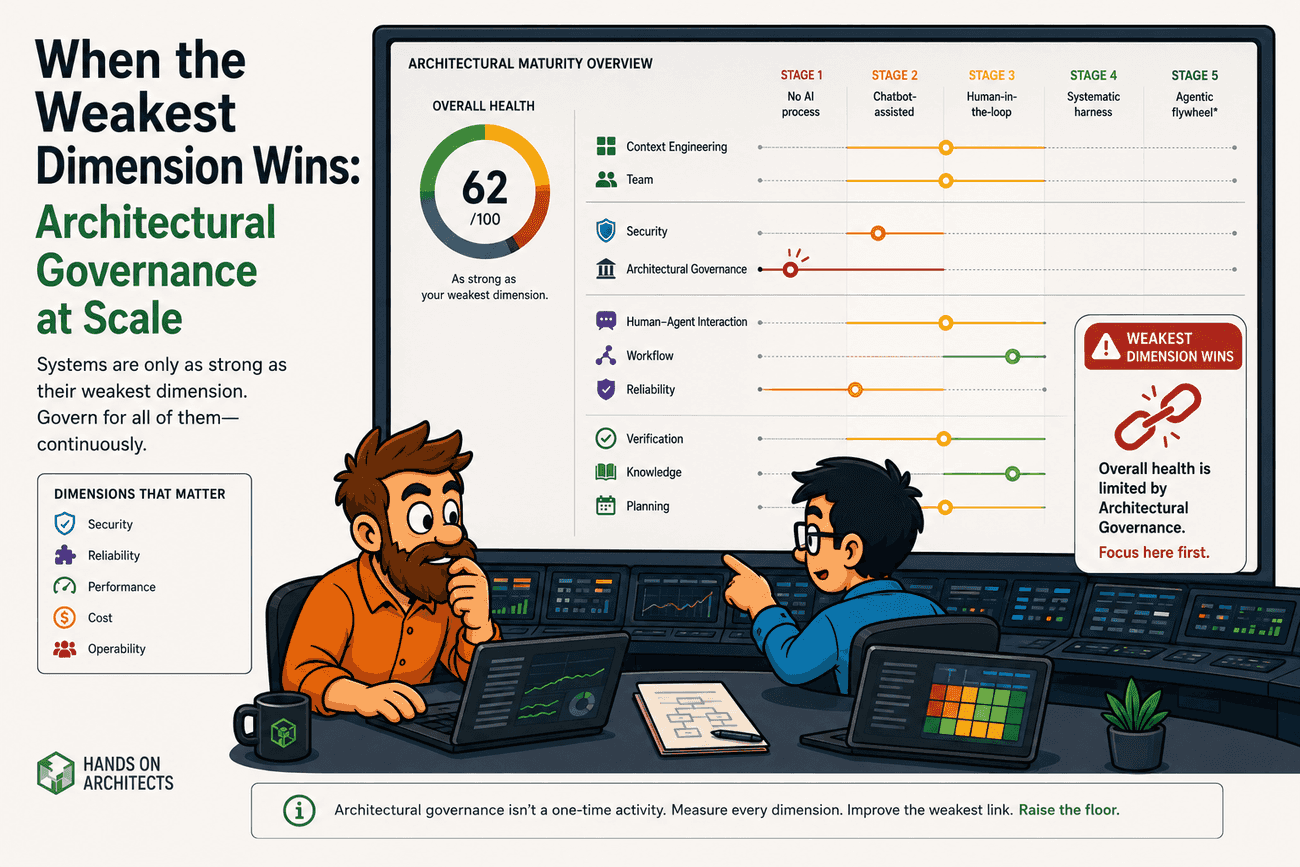
The Harness Model and the multi-dimensional nature of maturity
The short version: the Harness Model Maturity Matrix scores ten dimensions of AI-engineering practice, each across five maturity stages, so a team can see where it actually stands rather than where it feels like it stands. Those ten dimensions group into four clusters: Foundation (context engineering, team), Governance (security, architectural governance), Delivery (human-agent interaction, workflow, reliability), and Outcomes & Learning (verification, knowledge, planning). Each dimension has five stages: from "no AI process" (Stage 1) through "chatbot-assisted" (Stage 2), "human-in-the-loop" (Stage 3), and "systematic harness" (Stage 4) to the speculative "agentic flywheel" (Stage 5). The matrix is a diagnostic tool. It is not a certification, and Stage 5 is informed speculation, not a documented endpoint.
The central claim of the model is structural: maturity does not average across dimensions; the weakest dimension dominates the whole. A team at Stage 3 in context engineering paired with Stage 1 in verification does not operate at the mean. The higher stages still ship at their own velocity, but the lowest dimension accumulates structural debt that erodes the value of everything above it. Unlike Liebig's law of the minimum — where plant growth is capped by the scarcest nutrient with a hard physical bound — the weakest dimension here does not impose a zero-yield ceiling. The debt compounds until it dominates the outcome. The mechanism is value erosion over time, not an instantaneous cap. We lean on the Liebig framing because it captures the right intuition (the bottleneck is what governs), but the mechanism is more like compounding interest than a hard wall.
A concrete cross-dimension example: a team at Stage 3 in workflow generates code rapidly with AI assistance. The same team at Stage 1 in architectural governance has no linters, no structural tests, no codified invariants — boundary checks happen in code review or not at all. The Stage 3 velocity is real. Pull requests open and close faster than they used to. What also happens is that agent-generated code violates structural boundaries faster than humans can catch them manually. Six months later, the team owns more code, but the architectural shape has drifted. The Stage 3 speed shipped Stage 1 entropy. The weakest dimension dominated the outcome.
This is the lens we want to apply to a specific dimension and a specific class of platform.
Why AI platforms amplify the governance gap
We use an AI Platform as the running example because the governance tension is sharpest there. The reasons are structural, not particular to any organization. AI standards (Model Context Protocol servers, Skills) are changing constantly — what was a sensible abstraction in Q1 is a legacy compatibility layer by Q3. Business expectations are enormous and under continuous executive scrutiny. Market demand makes shipping speed non-negotiable, which amplifies the pressure to skip cross-team coordination. Multiple teams build simultaneously, each with strong local context and weak cross-team visibility.
Under these conditions, the architectural governance dimension — shared domain language, cross-team contracts, structural invariants, decision records — gets neglected not from negligence but from structural reality. Cross-team coordination requires cross-team ownership, and on a platform without a dedicated architect role, no single team owns it. Each team optimizes its own velocity. The aggregate cost is invisible until contracts collide.
A specific class of collision: domain vocabulary. Imagine a platform that distinguishes between four types of Model Context Protocol server — an Internal Platform Server (platform-owned, internal data access), an External Integration Server (platform-owned, external tool access), a Verified Community Server (third-party, audited), and a Custom Configuration Server (admin-configured, unaudited). Before this vocabulary is documented, two teams use these terms interchangeably. The collision surfaces at the security layer: a permission granted to "an external integration server" means different things depending on which definition was in scope when the rule was written. The fix at the documentation level is a ubiquitous language entry. The fix at the production level is an incident.
A bounded context is the boundary within which a particular vocabulary and model are valid — the unit at which a team owns its own naming. A domain ubiquitous language, in the Domain-Driven Design sense, is the shared vocabulary developed by engineers and domain experts and tested continuously against working software. For LLMs, the vocabulary is the contract. If it is precise and consistent, the model maps intent to implementation reliably. If it is vague or inconsistent, the model guesses — and it guesses faster than the team can catch the guess.
Unmesh Joshi makes this argument cleanly in "What Is Code?": code is a conceptual model of the problem domain, and vocabulary is how that model becomes visible. His framing of the risk: "The code may compile. It may even pass basic tests. But if the team does not understand the conceptual model behind those structures, the codebase has gained vocabulary without shared understanding." He calls the gap "cognitive debt." LLMs amplify it because they generate plausible vocabulary at a rate that outpaces a team's ability to develop shared meaning.
The knowledge base — making the platform model machine-readable
The first move in lifting architectural governance is making the platform-wide model machine-readable. The goal is concrete: when an engineer asks an agent "how does feature X interact with team B's component?", the answer comes back with structural context — bounded contexts named, ownership identified, contracts referenced, prior decisions cited. Not from memory. From the knowledge base.
That knowledge base has four components:
- A shared domain model: bounded contexts with their ubiquitous language entries
- Logical component-to-team mapping: who owns what
- Architectural diagrams that expose cross-team flows and invariants
- Architecture Decision Records (ADRs) that make implicit decisions legible
We will say more about the last two because they are the parts most often treated as documentation hygiene rather than first-class infrastructure.
The C4 model (Context, Container, Component, Code) is a framework for visualizing software architecture at four levels of abstraction. The Level 0 view — the System Landscape diagram — is the one that proves its value at platform scale. It puts every team's system on the same canvas. It shows cross-system relationships. Before a System Landscape exists, teams have no shared picture of the full platform to disagree with concretely. Disagreements happen in generalities. After it exists, principals from different teams can point at the same box and say "this is owned by my team, here is the contract" — or dispute the assignment. That is the point at which governance becomes possible: a common artifact that surfaces disagreements before they become migrations.
"Diagrams as code" is the second discipline. The diagram lives in version control, has a review process, and can be validated automatically — the same hygiene we apply to test suites. The diagram does not rot silently because automated checks (linting names, complexity thresholds, freshness timers) run on every change. The diagram is part of the build.
ADRs record the decisions: not just what was chosen, but the context, the alternatives considered, and the rationale for the chosen option. (We have written before about using generative AI as an architect buddy for ADRs.) For human teams, ADRs catch the "why did we do it this way?" question three months later. For LLMs, they do something more important: they make implicit decisions explicit context. A decision made in a Slack thread three months ago is invisible to an agent reasoning about a new feature. An ADR linked from the knowledge base is not.
A wiki has all of these things and decays anyway. The reason the knowledge base described here does not decay is not a semantic distinction. It is mechanical — the ingestion harness in the next section. This is the responsibility Mark Richards frames in Analyzing Architecture: Structural Decay: continually analyzing the architecture to keep it vital and to detect structural decay is part of the architect's job, not optional documentation hygiene.
Building the knowledge base — the ingestion harness
Maintaining cross-team documentation is hard for a known reason: teams fill templates under deadline pressure and produce consistency drift, silent gaps, and naming collisions that nobody flags until a contract breaks. On the platform we work on, we tried the template approach first. The output looked complete. It was not.
What works is a conversation-driven ingestion harness. The harness is an AI session that asks one focused question at a time, offers concrete options with their consequences, and refuses to accept a well-formatted document that has not been challenged. The pattern has three properties worth naming.
Conversation first, materialization second. The session is interactive. Every question comes with an initial proposal to reduce friction and boost engagement. The AI does not generate the documentation as its primary output — it challenges the model until ambiguity is gone. When the session ends, the findings are materialized into a review artifact in a staging area, not written directly into the canonical knowledge base.
Separate review and apply steps. The materialized session is a proposal. An explicit apply step, with per-item confirmation, is required before anything enters the canonical store. The human never has to fix AI-generated documentation inline — they approve or reject structured proposals. This is the "human on the loop" pattern Kief Morris describes in "Humans and Agents": "Rather than personally inspecting what the agents produce, we can make them better at producing it." The review step exists because the harness is not infallible. It is the last line of defense, not a formality.
Gap discovery as the working signal. The most useful feedback we have gotten from this process came from a platform principal engineer after one of the early sessions:
"I answered one question in a tricky way, there was a hidden gap. A while later I was asked exactly the question I had in my mind."
That moment — the harness arriving at the gap the participant already suspected — is the credibility anchor. The AI is not generating good documentation. It is arriving at the gaps the participant already half-knew were there. To stay honest about what this means: the harness surfaces what neither party is blind to — it cannot catch a shared assumption both the contributor and the model hold. The early sessions are a promising initial result with motivated principals, not a claim validated at scale.
The harness has evolved across iterations. The first version was a single advanced prompt — ~200 lines, embedding the full workflow, launched as a chat session. Value was immediate; the workflow was monolithic. The current version is split into small commands (start a session, apply approved findings, reject a session with reason) backed by a separate C4 model skill that validates structural rules: naming linting, complexity analysis, and maturity checks computed from git history. The maturity-policy timers flag a System Landscape diagram not updated in 12 months and a System Context diagram not updated in 6. The freshness signal is enforced automatically, not by convention.
Re-ingestion is triggered not only by those timers but by any platform update, by new approved or developed work (there is a documentation-update loop when new work ships), and by a monthly Principal meeting where direction is discussed and sessions are orchestrated when needed.
The honest note about maintenance: the harness makes ingestion tractable, not free. The ongoing cost is the human review cadence and the willingness to re-run sessions when the model changes. And freshness does not equal correctness — a diagram that is updated incorrectly generates false confidence. The harness reduces the cost of staying current; it does not eliminate it.
What this section describes is harness engineering applied to the documentation pipeline itself. Each iteration improves the system that produces the output, not just the output. The C4 skill is a Guide (a feedforward control on what the diagram should look like). The maturity check is a Sensor (a feedback control on whether it is still current). Both are part of the same discipline.
The decision harness — from knowledge base to governed decisions
The knowledge base is the foundation. The decision harness is where it pays off. With a shared domain model in place, a new feature can be analyzed with awareness of cross-team contracts, complexity, and cost — before implementation is committed to.
A note on confidence: the ingestion harness has been iterated through sessions with platform principals and produced the gap-discovery result above. The decision harness has not. It is at the plan and prototype stage — described from a design that has been worked through, not a production system that has run at scale. Treat the rest of this section as a designed pattern, not a validated result.
The harness uses a canvas adapted from the Structured-Prompt-Driven Development (SPDD) method by Thoughtworks. SPDD treats prompts as first-class delivery artifacts and structures them with the REASONS canvas (Requirements, Entities, Approach, Structure, Operations, Norms, Safeguards). The adaptation here is called REASINS: we substitute the O (Operations) for an I (Integration), which changes both the canvas and its name.
| Letter | Section | Purpose |
|---|---|---|
| R | Requirements | What the feature must accomplish; outcomes, constraints, success criteria |
| E | Entities | Domain concepts in play; bounded contexts and ubiquitous language entries that apply |
| A | Approach | High-level direction; the option chosen among the alternatives considered |
| S | Structure | Component-level shape; which components are affected, how they relate |
| I | Integration | API contracts and dependency edges between components (replaces SPDD's Operations) |
| N | Norms | Standards and conventions the solution must follow (naming, patterns, prior ADRs) |
| S | Safeguards | Explicit risk mitigations and failure-mode handling |
The Norms vs. Safeguards distinction is worth keeping in mind. Norms are what good looks like by default — the conventions that the solution should respect because the platform already runs that way. Safeguards are what the solution must do specifically to mitigate identified risks — the explicit "if this fails, here is the fallback" handling. Conflating them is how a canvas grows a section that looks complete but does not separate "follow the platform pattern" from "this specific risk needs this specific mitigation."
The reason for I (Integration) replacing O (Operations): SPDD's Operations section covers deployment, runtime behavior, and operational concerns. At the cross-team governance level, what we need instead is an explicit record of API contracts and dependency edges between components. The decision harness governs what crosses team boundaries. Operations stays with the teams who own the components.
To make this concrete, run the MCP-server permission feature through the canvas. Suppose a team wants to add a feature: "let platform admins grant a scoped permission to an external integration server." This is exactly the feature that, left ungoverned, produced the collision earlier — "external integration server" meant one thing to the security team and another to the team writing the rule. Here is how REASINS forces the ambiguity into the open before any code is written:
| Section | Populated for the permission feature |
|---|---|
| R Requirements | Admins can grant a scoped, revocable permission to an external integration server; the grant is auditable |
| E Entities | Pulls the bounded-context vocabulary: External Integration Server (platform-owned, external tool access) — explicitly not Verified Community Server or Custom Configuration Server, which carry different trust assumptions |
| A Approach | Permission resolved against the server's declared type at grant time, not at call time |
| S Structure | Admin console component and the permission-resolution component in the security context are affected |
| I Integration | The contract edge that would otherwise collide: the permission API must take a typed server reference, not a free-text "external integration server" string the two teams read differently |
| N Norms | Follows the platform's existing permission-naming convention and the prior ADR on server-type taxonomy |
| S Safeguards | If a server's declared type is missing or ambiguous, deny by default rather than fall back to the broadest scope |
The Entities row is where the bounded-context vocabulary stops being documentation and starts being a constraint: the canvas cannot advance with "external integration server" left as prose, because the entry has to resolve to one of the four named server types. The Integration row is where the collision is caught — it names the contract edge (a typed server reference) that the two teams would otherwise have implemented as a string each interpreted its own way. The documentation gap and the production incident are the same gap, surfaced before the code instead of after.
The lifecycle is gated. A canvas advances only when its sections are non-empty, affected components are named, and lifecycle checks pass.
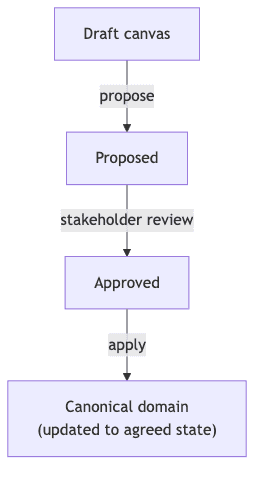
What the harness produces is a structured prompt per affected component, not implementation code. Teams receive the prompt and use whatever technique they prefer to plan implementation — spec-driven workflows, their own templates, plain pairing. Teams retain autonomy over how; the harness governs what crosses the seam. This is the design choice that keeps team independence intact while ensuring cross-team contracts are verified before implementation diverges.
The harness does not resolve domain model conflicts on its own. When two teams hold contradictory views on a shared concept, the harness surfaces the conflict, frames it as a structured question with options and consequences, and escalates. Resolution happens between humans. The harness produces the structured input that makes that conversation possible.
The payoff splits cleanly across roles. For engineers, the value is pivot speed at contract level. With the knowledge base loaded, the harness can answer "if we add multi-context state, which contracts change and in which sequence?" in a session rather than across a week of meetings. The cost of changing direction becomes visible while it is still cheap to change direction. For product managers, the value is informed scope decisions before the sprint hardens. The decision harness gives PMs a structured view of how a feature idea maps to technical complexity and cost, before implementation starts. A PM sees not a green/yellow/red signal but the actual contract changes a feature would require — which is the information needed to choose between "ship the small version now" and "fund the bigger change properly."
Context engineering at the architectural level — the Stage 3 → Stage 4 jump
The maturity matrix describes the architectural governance dimension at Stage 3 as "human-enforced boundaries; constrained solution space." Stage 4 is "custom linters with remediation; taste invariants as code." The jump between them is what this article has been describing, decomposed:
- The knowledge base makes the architectural model machine-readable and agent-accessible
- The ingestion harness keeps that model current and challenged
- The decision harness encodes cross-team governance into a reviewable, versionable artifact
- C4 diagrams as code plus maturity validation gives the architectural view a freshness signal
At Stage 3, context engineering happens at the per-engineer or per-team level. Each engineer maintains their own context — AGENTS.md, structured prompts, local conventions. Each team curates its own slice of documentation. At Stage 4, context engineering happens at the platform level. The domain context that crosses team boundaries is a core artifact with the same lifecycle discipline as code: versioned, reviewed, validated, refreshed.
The Harness Model thesis is that each stage unlocks the next. That is true. The corollary is what this article has been building toward: each stage also constrains the next. If architectural governance stays at Stage 1 while everything else advances, the higher stages do not disappear. They accumulate debt. The weakest dimension does not impose a hard ceiling; it erodes the returns from everything above it. Individual velocity continues. The aggregate cost grows invisibly until contracts collide.
15-minute exercise
Pick a team you work with — yours, or one you collaborate with. Sit with these three questions and answer them out loud, not in your head:
- Do your teams share a documented domain vocabulary that both humans and LLMs can read — and is that vocabulary tested against working software, not just agreed in a meeting?
- Are your architectural invariants enforced by tooling (linters, structural tests, maturity checks), or by code review? When a boundary is violated, how long before anyone notices?
- When a new team joins the platform, is there a structured way for them to ingest the existing contract surface — or does orientation happen through word of mouth and Slack threads?
These are diagnostic, not rhetorical. A team that cannot answer the first affirmatively does not yet have the substrate for a Stage 4 knowledge base. A team that cannot answer the second is running architectural governance as tribal knowledge — Stage 3 at best, regardless of how good its individual harness looks. A team that cannot answer the third is treating governance as a per-team property, which it is not: governance that lives in one team's heads is not platform governance.
Spend the remaining minutes writing down one concrete artifact you could ship next week to move from a "no" to a "partial yes" on whichever question stung the most. A System Landscape diagram in version control. A first ADR. A glossary entry for the three terms your teams use differently. The first artifact is the one that costs the least and surfaces the next gap.
Conclusion
Task-level metrics will keep getting noisier. METR has been honest about why: the more AI adoption spreads, the harder it is to construct a control group, and the more the question itself drifts away from what teams actually want to know. Platforms are not built one task at a time. They are built by multiple teams converging on shared decisions about contracts they will all live with.
Architectural governance is the dimension that crosses team boundaries. On an AI platform — where standards shift faster than annual planning cycles and where multiple teams ship in parallel — it is also the dimension most likely to lag while everything else advances. The Stage 3 → Stage 4 jump is not a tooling decision. It is the decision to treat context engineering as an architectural practice, not a per-team one: a shared domain model, an ingestion harness that keeps it current, a decision harness that turns cross-team disagreements into structured prompts before implementation diverges.
The weakest dimension dominates the outcome. The question is whether the architectural governance dimension dominates by design — through a governed system that is owned, maintained, and machine-readable — or by neglect, through the cost of a migration nobody budgeted for. Both options ship code. Only one ships a platform.
TL;DR
On an AI platform, maturity doesn't average across dimensions — the weakest one dominates the outcome. Here are some signs that architecture governance is your weakness: AI standards shift faster than planning cycles, multiple teams ship in parallel, and on a platform without a dedicated architect role, no single team owns the cross-team seam.
The cost stays invisible until contracts collide. Two teams use "external integration server" to mean different things; the collision surfaces at the security layer, and a documentation gap becomes a production incident. For an LLM the vocabulary is the contract — when it is vague, the model guesses, and it guesses faster than the team can catch the guess.
The way out is to stop treating context engineering as a per-team habit and make it an architectural practice. That starts with a machine-readable shared domain model — bounded contexts, C4 diagrams as code, and ADRs — kept current by a conversation-driven ingestion harness that challenges the model until ambiguity is gone and materializes findings into a reviewable artifact rather than writing straight into the canonical store.
A decision harness then turns cross-team contracts into reviewable artifacts before implementation diverges. It runs a feature through a REASINS canvas — Thoughtworks' REASONS adapted to swap Operations for Integration — which forces ambiguous vocabulary to resolve to a named entity and catches the contract collision before any code is written. The harness governs what crosses the seam; teams keep autonomy over how they implement.
That is the Stage 3 → Stage 4 jump: context engineering as a platform artifact with the same lifecycle discipline as code. Both neglect and design ship code; only one ships a platform.