
At the Pragmatic Summit, Martin Fowler asked the question every technology leader reorganizing around AI is circling: "Are we seeing two-pizza teams becoming one-pizza teams because agents don't eat pizza, or do we see two-pizza teams staying and becoming much more effective and capable? My bet is on more effective two-pizza teams." It sounds like a question about headcount (since two-pizza team is 5-8 people, then one-pizza team would be 3-4?). We think it is really a question about where the cognitive load goes.
Team Topologies is usually read as a book about org design. Its engine is something narrower and more useful: cognitive load as a finite, per-team budget. Every team type the book defines is a different way to keep one team's budget from overflowing. An AI harness is a new lever on exactly that budget — so in this post we re-read all four team types through one question: when the harness moves the cheap load, where does the expensive load end up?
An AI harness is a cognitive-load lever — which is what platform teams do
Terms first, because "harness" is a contested word. We use it the way Birgitta Böckeler does in Harness Engineering, and the way our governance post already does: a harness is everything in an AI agent except the model itself.
Agent = Model + Harness
The harness is the context the agent reads, the tools it can call, the guardrails and linters and tests that check its output, and the feedback loops that improve all of those over time.
Now the Team Topologies side. The book defines exactly four team types — stream-aligned, enabling, complicated-subsystem, and platform — and exactly three interaction modes: collaboration, X-as-a-Service, and facilitating. We built on this foundation before, in Services Architecture and Code Ownership. The part that gets lost in re-tellings is why the types exist: a team's cognitive capacity is finite, and when the domain it owns exceeds that capacity, delivery slows, quality drops, and people burn out. The other three types exist to absorb load off the stream-aligned team, so it can stay focused on its stream.
Read the harness's job description against that. It absorbs boilerplate, glue code, codebase search, and first-draft implementation off a stream-aligned team. That is the exact job description of a platform team. This is not just our analogy: the platform engineering community explicitly describes its own discipline as cognitive-load mitigation.
Which raises the tempting move: should the team that builds the org's harness be crowned a new, 4.5th team type? Team Topologies is emphatic that there are four types and no hybrids — and we think it is right. The "what type is it?" question is the wrong one. Ask instead: whose load does it reduce? A team that builds and operates the harness — context templates, agent workflows, eval loops, guardrails — is a platform team whose product happens to be the harness. It is consumed the way Team Topologies says platforms should be consumed: X-as-a-Service, behind a clear interface (a well-designed MCP server is exactly that interface — and, as we return to at the end, perhaps a Conway's Law force of its own), with governance baked into the harness rather than enforced in review — architecture tests that fail the build are the canonical example.
Here is the whole argument in one picture. Watch the return arrows — every load the harness platform takes off the stream team sends something back.
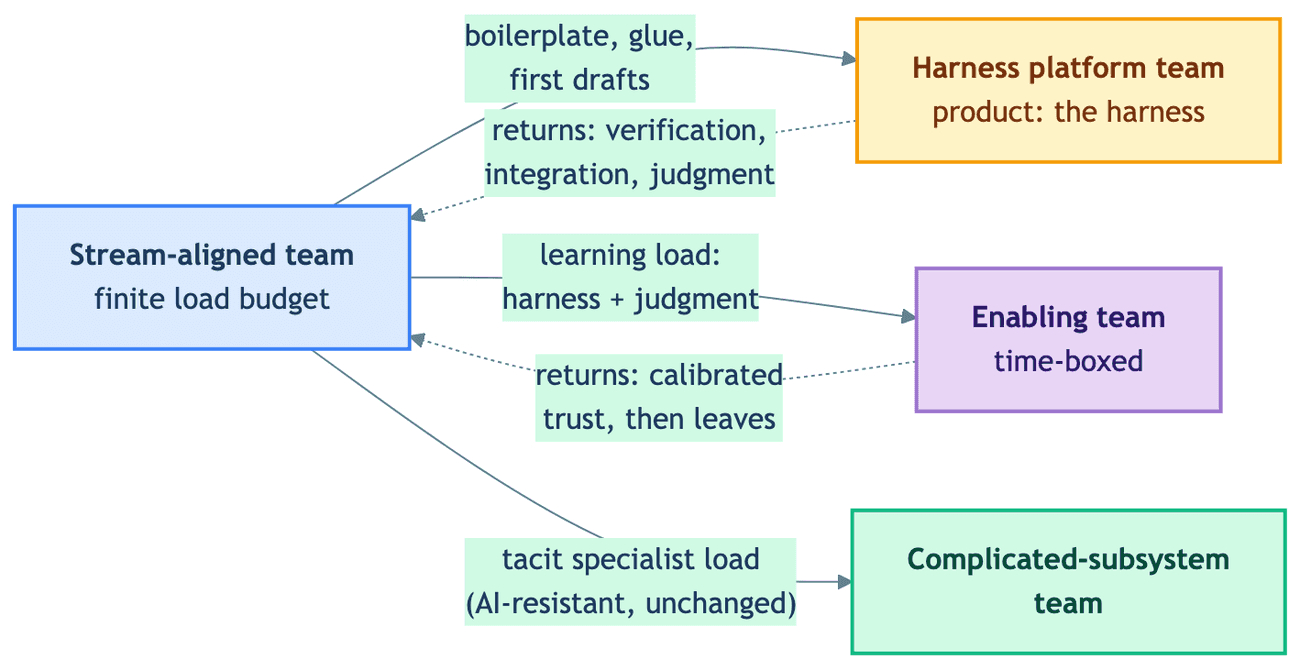
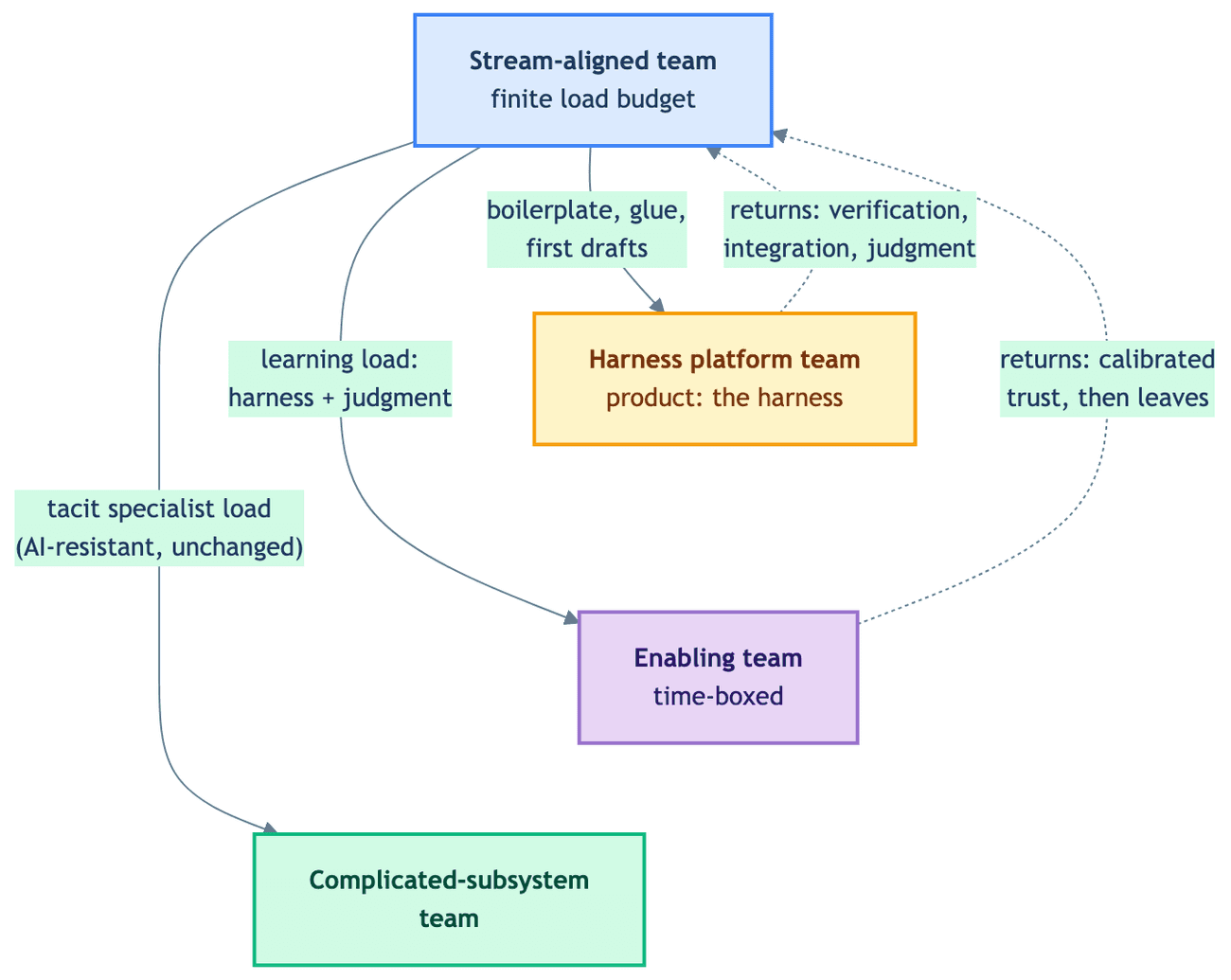
Stream-aligned: the Product Engineer question
The stream-aligned team is Team Topologies' default: five to nine people owning a slice of the product end to end. It is also the team type with the most at stake in the AI era, because it is the team the harness was built for. A wave of practitioner writing has already renamed its members — the Product Engineer, a generalist who, amplified by agents, spans design to code to operations.
So which way does Fowler's question break? Does the team shrink to fewer generalists — or hold its headcount and own more scope? Both forks are live, and we are not going to pretend the data settles it.
What we can say is what the surviving work looks like. Kent Beck, on the same Summit stage, described his experience of pairing — two humans plus a genie — and praised the genie's slowness: "When the AI goes away for three minutes, we can talk about our philosophy of naming, or how we express conditionals, or about what we should be doing next." That three-minute gap is not idle time. It is where the irreducible work happens: deciding what to build, judging what came back. The genie generates; the humans verify and steer.
Beck also supplies the brake on the strongest "smaller teams" reading: "AI is an amplifier." We made the same argument in How to Start using AI in Software Development — an amplifier does not subtract team members; it changes what each one carries. It also resolves a tension with Services Architecture and Code Ownership, where we argued that a stream team should own its services full-lifecycle: a leaner team does not break that argument, it concentrates it. The verification load is the new weight of ownership.
One more data point, from inside a 4,000-engineer AI-forward organization: Jamie Hurst reports that the compression runs upward. "The work that used to need a team now sometimes needs one person with the right tools, and that person tends to be senior because seniority is where the system-level understanding lives." The generalist who absorbs the team is senior — and Hurst is blunt that it is not free: "the role isn't sustainable at this pace." A field report of one, but worth sitting with.
Enabling: consultants who teach calibrated trust, then leave
The Team Topologies authors' 2025 guidance on interaction modes sharpened something the book always implied: collaboration is temporary by design, and facilitating is self-terminating — entry and exit criteria are part of the mode. That maps one-to-one onto a model we expect to see everywhere: a small group of consultants — internal or external — who introduce the harness to a stream team, then leave.
The scope matters. The job is not installing the harness; the job is teaching the team to carry the verification load the harness creates. "Calibrated trust" sounds soft, so make it concrete:
- When to override the agent. Anywhere the work touches domain rules no sensor in the harness checks — correctness is outside the harness's remit when nobody specified it.
- How to tell the harness itself is wrong. If the guardrails never fire, treat that as a smell, not a triumph: either quality is exceptional or detection is inadequate.
- What honest verification looks like. "We merged it because the tests are green" is not verification when the same agent generated the tests.
The exit criterion writes itself: the enabling team leaves when the stream team can answer those three without them in the room.
Hurst's field report shows why this work needs an explicit owner. In his organization, mentoring and 1-2-1s were "the first thing to go" — precisely because they are the load AI does not absorb. Unless someone is accountable for transferring judgment, it silently disappears from everyone's calendar. The cheapest defense we know: write the engagement's exit date, exit criteria, and a named owner into the kickoff doc on day one — that single line keeps the facilitating mode self-terminating and the judgment transfer on someone's accountability list. We argued the upskilling half of this years ago in Just-in-time Knowledge Sharing; what that post stopped short of, and Team Topologies supplies, is the time-box — the exit date.
Complicated-subsystem: the AI-resistant boundary
If you had asked us in 2024 which team type AI would dissolve first, we would have guessed this one: specialists, absorbed by models trained on everything. The early evidence points the other way. A CHI 2026 study found AI assistance is weakest exactly where tacit, specialist knowledge matters — the settings where you cannot easily verify the output because the expertise lives in people's heads. One study, n=60, so treat it as directional rather than definitive. But it matches a nuance our own maturity matrix already states: agents provide technical depth on demand — frameworks, languages, patterns — not domain depth.
Re-read the complicated-subsystem team through the load lens. It exists so stream-aligned teams do not have to carry deep specialist load — the video codec, the pricing engine, the ML internals. The harness relocates generalist load; it cannot relocate tacit-specialist load, because tacit knowledge is precisely the kind you cannot write into a context file. So of the four types, this team's load budget is the least changed by AI. Everyone else's work got cheaper to generate; theirs did not.
That inverts the intuitive prediction: the complicated-subsystem team is not the first boundary to dissolve — it is the most durable one. There is a sharper, forward-looking version of this idea (if AI is weakest at tacit knowledge, is tacit knowledge now a reason to draw a boundary?), but it rests on that same single study, so we hold it for the open questions at the end.
The Stage 3→4 jump: load relocated, not removed
Time to name what we have been planting all along. In the Harness Model, our maturity matrix for AI engineering, the Team (Humans + Agents) dimension moves from Stage 3 — "Leaner delivery-minded team; agents use file/terminal" — to Stage 4 — "Small generalist team per initiative; agents run full stack." The matrix states the shape of the jump. This post is about its mechanism and its price: The harness does not delete cognitive load. It relocates it.
Generation gets cheap; verification, integration, and judgment get expensive. The CHI study gives the receipt: verification load is measurable and mediates fatigue — more checking means more tiredness, even while raw output climbs. The Stage 3→4 jump is that trade executed deliberately: the team can get leaner only because the platformizable load left — and it stays viable only if it can pay for the load that came back. Here is the stream team's ledger across the jump:
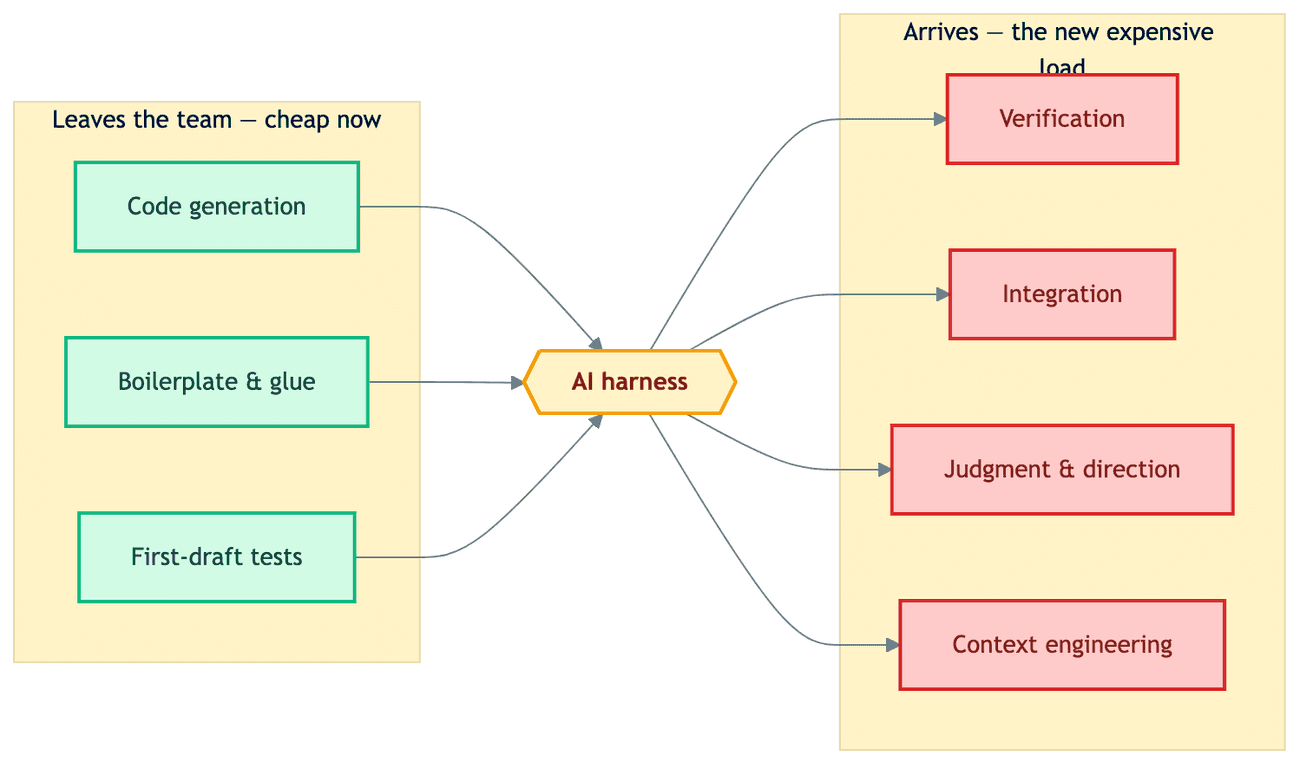
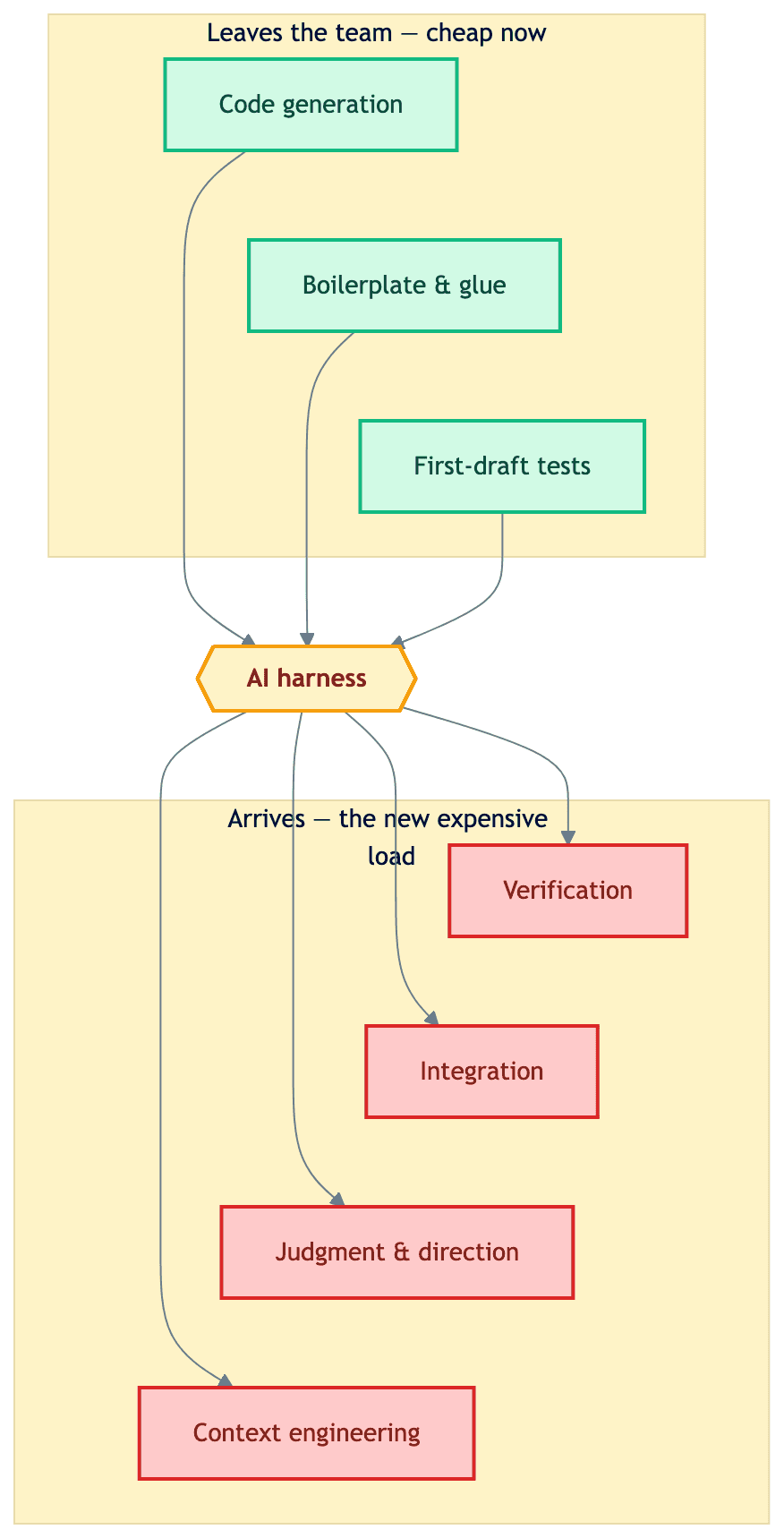
To make the ledger less abstract, picture a five-person stream team a quarter into the jump — a composite sketch, not a case study. Nobody on it hand-writes boilerplate, glue code, or first-draft tests anymore; the agents do. The hours that work used to fill now go to reviewing agent output before it merges, making the integration calls the agent cannot make, keeping the context files current enough that next week's drafts stay trustworthy, and learning. Same five people, same forty hours — every line item moved.
The matrix already says this in its own voice: "Teams that try to shrink without paying either cost end up with the same number of humans and less agent trust."
And here is where we push on our own model. The matrix commits to "small generalist team"; Fowler bets on more-effective same-size teams. We now think the next revision should assert less and explain more: hold the headcount open, assert the load relocation. The relocation is what the evidence supports; the headcount is downstream of where the relocated load lands, and that differs by team and by domain. The Q1 matrix is explicitly a snapshot built to be revised — consider this our first input to its next version.
Hurst compresses the whole thesis into one sentence: "The cost of building has collapsed, but the cost of aligning organisationally has not." One practitioner's report — but it is exactly what relocated load looks like from the inside.
The Software House angle: the harness is the IP
A deliberate gear-change here, from org design to economics — and if you are not in the agency business, stay anyway: everything below applies equally to any organization running many product teams on a similar stack. For a Software House, the relocation thesis has a commercial consequence. Relocated cognitive load does not evaporate — when relocation is done well, it gets captured: in context templates, eval loops, guardrails, agent workflows. Captured relocation is durable and reusable. The model is rented; the harness is owned.
The mechanism is well supported: harness design, not the model, drives outcomes. One benchmark cited by Hugging Face moved from 61.5% to 87.2% on the same model through harness design alone. Our own E2E test harness is the worked proof at small scale: sharper specs and a better harness cut commits per test step roughly 5× while CI time stayed flat — with the leverage in the spec, not the model.
The inference we draw from that — and it is our extrapolation, not a finding — is that a Software House accumulating proven harness templates starts every project ahead: faster delivery, more consistent quality, and an asset that survives model churn because a good harness re-targets to the next model. Before anyone turns that into a sales deck, two brakes:
- Experience precedes platform. You cannot harness-platformize patterns you have not lived. The harness platform should be extracted from a few real engagements — thinnest-viable, demand-pulled, exactly the rule Team Topologies applies to every platform. Building it speculatively is premature optimization with a roadmap.
- ROI scales with stack homogeneity. Harness templates behave like service templates: cheap to reuse across twenty similar Spring Boot services, expensive across twenty different stacks. A heterogeneous portfolio pays more to platformize and gets less back.
The economics are moving this way regardless. Hurst again: a piece of internal platform that previously served 4,000 humans "now potentially serves 4,000 humans plus an unbounded number of agent instances those humans deploy." The industry is starting to call this agent experience, and it is moving platform investment from team-level to board-level priority. A harness platform team is that investment with a name and a team type.
What we can't settle yet
Three questions we are deliberately leaving open — not because they are unanswerable, but because answering them today would be guessing:
- The headcount fork. Do stream-aligned teams shrink, or hold headcount and own more scope? Fowler bets on more-capable two-pizza teams; our matrix currently bets on leaner ones.
- Conway's Law with agents. If an agent is a communicating participant in building the system, does Conway's Law now describe human↔agent and agent↔agent communication — and is choosing a harness a reverse-Conway move, shaping architecture by shaping the agent topology? The matrix's "agents are first-class team members" principle is the on-ramp; nothing stronger than practitioner speculation exists yet.
- Tacit knowledge as a fracture plane. If AI is weakest at tacit knowledge, does tacit knowledge become a place to draw team boundaries, not just defend them? We think so. Nobody has tested it, and the supporting evidence is one n=60 study.
All three are inputs to the next, post-Q1 version of the Harness Model. This post is meant to shape that model, not just apply it.
If you want to do something with this tomorrow: run each of your teams through the one question this post runs on — whose cognitive load does this team reduce, and what load flows back? Then self-assess on the Team dimension of the matrix. And if your answers disagree with ours — especially on the headcount fork — argue with us: email contact@handsonarchitects.com or DM either of us on LinkedIn: Maciej · Tomasz. The best version of this argument is the one we have not heard yet.
TL;DR
AI coding agents do not delete engineering work — they relocate it. Writing code gets cheap; checking it, integrating it, and deciding what to build stay human and become the expensive part. Any plan built on "AI means fewer engineers" without asking where that expensive work lands is budgeting from half the ledger.
On headcount, the honest answer is that nobody has reliable numbers yet — even the best study keeps correcting itself. Martin Fowler bets teams stay the same size and become more capable; our own maturity model bets on leaner teams. Both outcomes are live. What is certain either way: each remaining person carries more reviewing and judgment per head, so budget for that load, not just for seats.
The tooling around the AI — the harness: the context, guardrails, and workflows wrapped around the rented model — is where the results actually come from, not the model itself. Treat the team that builds it as a real product team, not a side project. For a Software House this is the commercial headline: everyone rents the same models at the same price, but the harness is owned, and it compounds — every new project starts ahead. Two cautions before that becomes a sales deck: build it out of a few real projects rather than speculation, and expect the return to scale with how uniform your tech stacks are.
One counter-intuitive staffing signal: your deep specialists — the people whose value is hard-won knowledge that lives in their heads, not in documents — are the least exposed to AI, not the most. AI is weakest exactly where unwritten expertise matters. Plan around keeping them.
The single question worth running every team through at your next org review: whose workload does this team reduce — and what work flows back when it does? Then place yourself on the Team dimension of our maturity matrix.